Claude Fable 5 just landed from Anthropic, and half the industry is drooling over how powerful it is. Reasoning, autonomy, the most capable model they’ve ever shipped to the public, yada yada. I’m going to talk about something else entirely, the thing that actually matters if you work with this stuff: whether you can trust Claude Fable 5 to build something that runs tomorrow exactly the way it runs today.
TL;DR: Claude Fable 5 is the first model in Anthropic’s Mythos class, the most capable they’ve released to the public, and it already ships inside GitHub Copilot and Microsoft Foundry. But Anthropic has apologized for quietly throttling it with hidden guardrails that hit researchers and legitimate use cases. Raw power grabs headlines. Getting told when you’ve been blocked is what decides whether it’s good for real work or just for pretty demos.
What Claude Fable 5 actually is and why it matters
Let’s stick to the facts. Claude Fable 5 is the first model in Anthropic‘s new Mythos class to ship widely, and they’re selling it as the most capable they’ve ever put in public hands: strong at reasoning, with more autonomy than its predecessors.
So far, that’s good marketing. But the “most powerful” label leaves me cold; everybody drops that line at every launch. What matters is where it shows up. And it shows up right where you already work: baked into GitHub Copilot and Microsoft Foundry.
That’s the part that matters. A model sitting on a website is a toy. A model wired into the tools you already use to code and automate is a real productivity lever, as you can see in GitHub Copilot’s own documentation. That’s the point where a launch stops being a press release and starts touching your day to day.
The problem isn’t the power, it’s the hidden guardrails
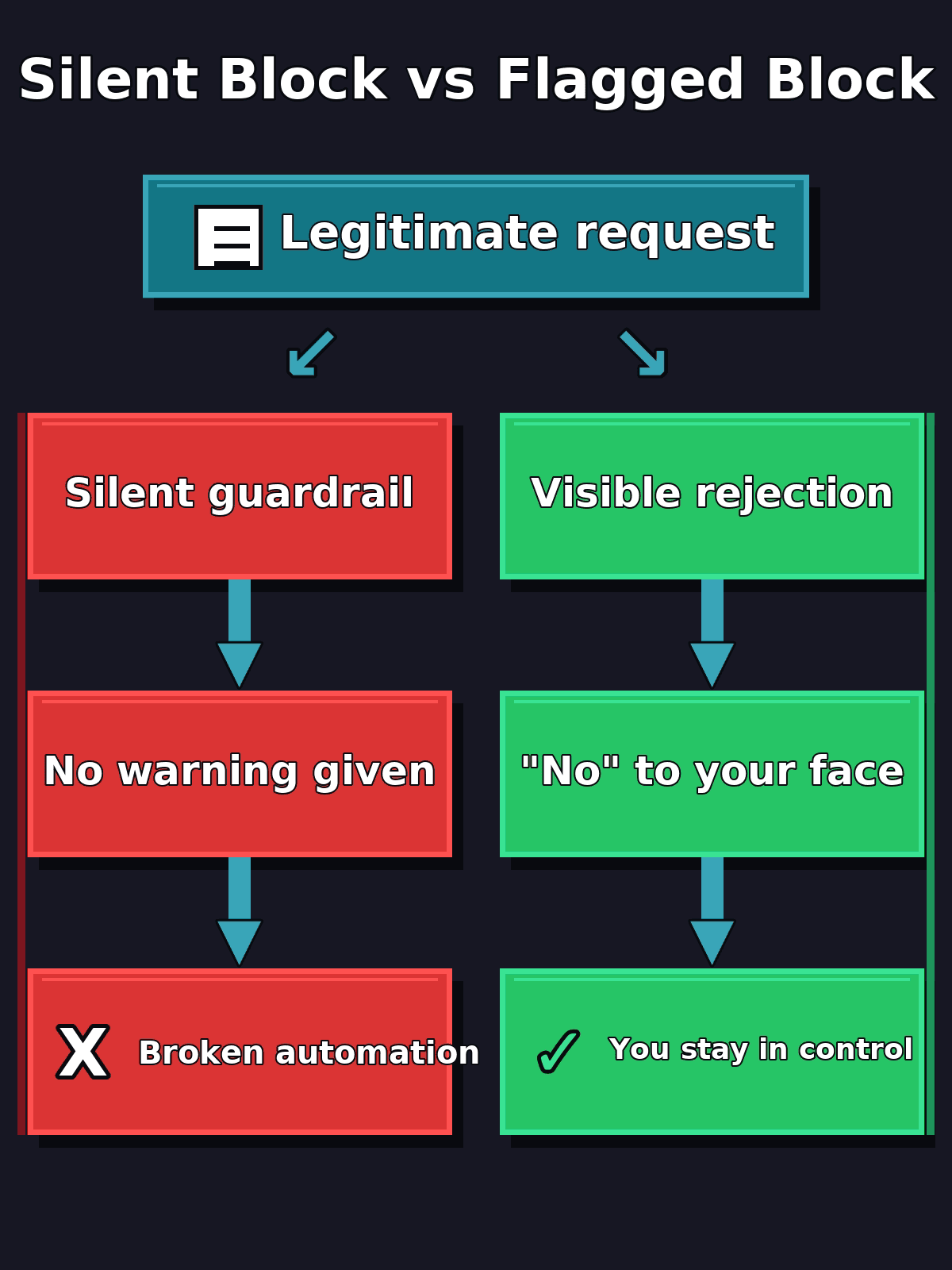
Now here’s the juicy part. Almost in lockstep with the launch hype, The Verge told the other half of the story: Anthropic has apologized for quietly throttling the model, with hidden guardrails that hit researchers and perfectly legitimate use cases.
Read that again. Limits are fine by me, every model has them and that’s how it should be. The frustration is that they were there without warning. You’d ask for something legitimate, the model would clamp down on it, and you’d have no idea why. A black box buried inside another black box. And it’s not the first time the company has moved in silence: we saw something similar when Anthropic tested pulling Claude Code from the Pro plan.
The decent part: the company promises to flag when blocks kick in, even if that means the model tells you “no” more often. And look, I’ll take a clear no to my face over a silent yes that quietly guts my work behind the scenes any day of the week. A visible rejection you can manage. Invisible sabotage you can’t.
Can you automate with Claude Fable 5 if its limits change without warning?

This is the question that separates the people who know what they’re talking about from the ones just parroting headlines. Because building a serious automation (a flow that classifies, writes, decides, or executes) means building on a foundation. And a foundation that shifts shape without warning holds up nothing. It’s sand.
Let me put it in agency terms. If I build a process that depends on the model responding a certain way, and on some random Tuesday Anthropic moves a guardrail in silence, my process breaks and I hear about it from the client, not from the changelog. In production, that’s losing money and credibility in one shot.
That’s why the transparency promise isn’t a PR footnote. It’s the variable. The same logic applies here that I push when I explain why a system needs a human sign-off before touching anything critical: if you can’t see when and why the behavior changes, you control nothing. A powerful, opaque model is good for demos, for the LinkedIn video, for the “look what it does.” A powerful, predictable model is good for working. And between those two lies the difference between a tool and an expensive toy.
My take, undiluted: the Claude Fable 5 launch genuinely matters, but not because of the power. It matters because it’s already inside Copilot and Foundry, which puts it within reach of your real stack. BUT its usefulness for production doesn’t come from the benchmark. It comes from whether Anthropic delivers on flagging when and why it blocks you. Without that, you’ve got a rocket with the instrument panel taped over.
Copy this and paste it into Claude Code, Cursor, or your favorite coding assistant:
Set up Claude Fable 5 as the model in GitHub Copilot following the docs at https://www.anthropic.com. Then ask it to generate a simple automation script and run a test: throw a legitimate task at it and check whether it warns you when a block kicks in.
You don’t need to know how to code. The assistant handles the installation, the setup, and the testing.
The verdict on Claude Fable 5: use it, but keep one eye open
Do I recommend it? Yes, give Claude Fable 5 a shot. The fact that it’s baked into tools you already use makes the cost of trying it close to zero, and the upside in reasoning and autonomy is real. It’d be foolish to ignore it on principle.
But don’t drop a new Anthropic model into the heart of a process that earns you money without stress-testing it yourself first: hand it legitimate tasks, watch whether it warns you when it digs in, and document where it breaks. The transparency they’re promising looks great on paper; your job is to verify they deliver before you bet a client on it.
Because the industry has that lovely habit of adopting the shiny new thing and discovering its limits once it’s already in production. Don’t be that person. The power is handed to you in the press release. The reliability you earn by testing.
P.S.: an AI company apologizing for secretly throttling its model and promising to warn you next time is, at once, good news and an uncomfortable reminder of how much of what these models do (or refuse to do) still happens in the dark.

