“Switching AI models is just swapping an environment variable.” You’ve read it a hundred times. It’s a lie. My pipeline depended on the exact format of the wrapper the tool built around each response. The model itself? Irrelevant. And that’s exactly where almost every AI model migration crashes.

TL;DR: The No-Nonsense Summary
- Two-layer contract: Your pipeline reads the wrapper the tool puts around the output, not the model itself. Swap the model and the wrapper breaks.
- 40-line shim: An adapter that rebuilds the exact wrapper for the new engine. Your pipeline never notices the change.
- €0.0015 per run: 25x cheaper than the previous setup, verified in production.
- Adversarial critic: A second model caught 22 bugs before anything touched production, including a private data leak.
Here’s how we got here. Anthropic decided to change the rules of the game with headless agent billing. Just like that, the way a landlord slips a rent hike notice under the door. The result: my entire automation ecosystem went up in smoke. And when I say everything, I mean everything.
The truth is, I was scared. I had a content pipeline that worked, that was battle-tested, and that had just proven itself dependent on a vendor that could change the rules overnight. The plan: switch to OpenCode with a mixed-model setup, DeepSeek for heavy lifting, OpenAI for specific tasks. Seemed doable.
Until I looked under the hood.
Why switching AI models is never a true drop-in replacement
The idea sounded simple: swap the model and move on. One is 25x cheaper. What could go wrong?
Everything.
I call it the two-layer contract. Layer 1: what the model actually returns, the raw text. Layer 2: what the tool does with that response before handing it to your code. A wrapper carrying metadata ({result, session_id, cost, model...}). And what did my 20 downstream scripts actually read?
The wrapper. Always the wrapper.
The entire pipeline was coupled to the wrapper format. What intelligence lived inside was completely irrelevant. DeepSeek speaks a different dialect: where you expected clean JSON wrapped in ribbon, you get a stream of events. A “drop-in” swap broke absolutely everything, filtering, formatting, storage.
Rewriting 20 scripts was not an option. Not even close.
The 40-line shim that migrates your AI pipeline without touching it
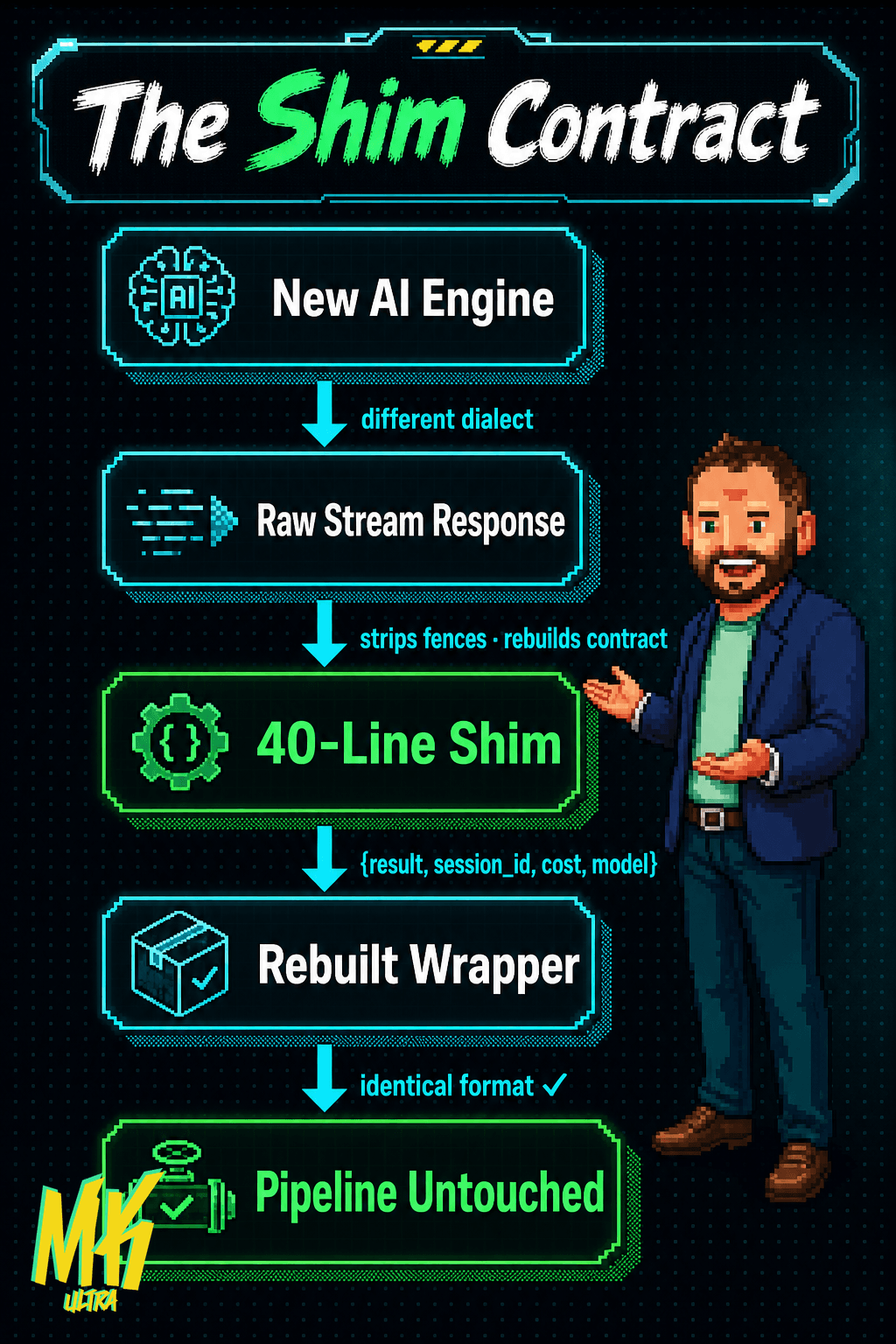
So I did the only thing that made sense: a 40-line adapter. It calls the new engine, collects the response, and reconstructs the exact output format the pipeline already expects. The existing handler consumes the output without ever knowing its brain was swapped.
Same fields. Same structure.
Including the ugly detail of stripping the ```json``` markdown fences that models love to smuggle into their responses. The kind of mess no tutorial ever mentions but that kills your parser at 3am, and no, I’m not exaggerating.
Your pipeline doesn’t care which model is running underneath. It just wants data in the shape it expects. Respect that shape and you can swap the brain without the body ever noticing.
Verified end-to-end on the production machine. Identical filtering, identical formatting.
Cost per run: €0.0015. 25x cheaper than the previous setup. If you’re looking to cut AI tooling costs without sacrificing quality, the analysis on Ponytail for Claude Code covers exactly that.
Pennies. Literal pennies.
How many bugs does an adversarial critic catch before production?

Before running anything in production, I did something I’d recommend to anyone moving parts around in an AI pipeline: put the entire plan through an adversarial critic. A second model, in read-only mode, whose only job is to find holes in your plan. To try to break it before reality does.
It found 22 bugs.
But the big one, the one that would have kept me up for weeks, was this: a job tagged as “public” could drag private data from shared memory over to the new provider. Private data traveling to a third party with zero controls in place.
You want to know what would have happened if that had reached production?
I’d rather not think about it.
If you’re moving the plumbing on your AI system, put another model to work trying to break your plan before you execute it. It’s cheap and it saves you headaches that no amount of money can fix. A QA reviewer that never sleeps and has no mercy for your ego.
The Plan B you need ready before migrating AI providers
Anthropic pulled this move on me. Tomorrow it could be OpenAI. Or Google. Or anyone. AI companies are going to keep making moves that directly affect your operations, and they are not going to ask for your permission. That’s just the reality.
What I do now at Marketing Ultra: every time I finish a pipeline or an automation flow, the next phase, always, is getting Plan B ready. With the adapter built and the alternative provider tested. Not “I’ve thought about it.” Ready. When the moment comes, you swap the adapter and go. If you want to understand how a full content pipeline is structured without manual review at every step, the piece on automating content with AI at scale gives you the full picture.
Speaking from experience: the first time you have to migrate under pressure, without a plan, you break into a cold sweat. The second time, if you’ve done your homework, it’s a thirty-minute chore.
The technical key is real decoupling, not decoupling on paper. Identify the exact boundary where your system consumes AI: what fields it reads, what shape it expects, what it assumes. Build an adapter that preserves that contract. That way you switch providers whenever you want without touching your business logic. If you want to see the real difference between raw power and production reliability before locking in a provider, the analysis on Claude Fable 5 in production is worth a read.
The only thing you actually migrate is the contract.
And whoever understands that won’t be rewriting 20 scripts at 3am the next time they have to switch AI providers. They’ll be changing an environment variable.
That one, yes.
Frequently asked questions about AI model migration
What is the two-layer contract in an AI model migration?
The two-layer contract describes your pipeline’s real dependency: layer 1 is the text the model returns, and layer 2 is the metadata wrapper the tool builds around it. Your code only ever sees layer 2. That’s why migrating AI models without an adapter breaks everything downstream.
What does it actually cost to switch AI providers in production?
The technical cost can be near zero with a well-built shim. The operational cost can drop 25x, in this case we moved to €0.0015 per run with DeepSeek via OpenCode. What actually gets expensive is not having it prepared in advance.
What is an adversarial critic and what does it do in an AI pipeline?
An adversarial critic is an AI model configured to review your plan with one objective: find flaws. Its job is to hunt for gaps, full stop. In the migration documented here, the critic found 22 errors before production was touched, including a private data leak between memory spaces.
How do I avoid vendor lock-in in my AI pipelines?
Identify the exact boundary where your system consumes AI and encapsulate it in an adapter. If that adapter is the only piece that knows about the real provider, the rest of the pipeline is agnostic. When the provider changes the rules, you rewrite the adapter, not the 20 business logic scripts behind it.

