Le colamos deliberadamente un titular falso con un dato inventado a nuestro propio pipeline de contenido con IA.
El agente editor jefe lo cazó, reescribió el titular a uno fiel pero atractivo y justificó cada corrección. Todo automático.
Pero lo gordo no es eso. Sin ese agente, el titular habría llegado al blog. Publicado. Indexado. Con una cifra que no existía en ninguna fuente. Y ninguno de los demás agentes del pipeline habría dicho ni mu.

TL;DR: El resumen sin rodeos
- El orden importa más que el número: reorganizar los agentes como una redacción (editor jefe antes que SEO) eliminó el defecto que desincronizaba títulos y contenido.
- Un gate editorial lo cambia todo: un agente cuya única función es vetar cazó un titular falso con dato inventado que los demás dejaron pasar.
- La IA fabrica URLs: los modelos inventan enlaces con formato perfecto pero que apuntan a páginas inexistentes. Validación automática obligatoria.
- Escalar sin criterio es escalar basura: más agentes no significa mejor contenido si ninguno tiene autoridad para frenar la publicación.
El defecto de diseño que todo el mundo copia
Un pipeline de contenido con IA es básicamente una cadena de agentes (redactor, optimizador SEO, rewriter, humanizador) que se van pasando el artículo hasta que sale publicado. La lógica habitual dice que cuantos más agentes, mejor sale el texto. Más pases, más «calidad».
No.
Auditamos nuestro pipeline de arriba abajo y encontramos un defecto tan obvio que daba vergüenza: el texto se reescribía varias veces DESPUÉS de optimizarlo para SEO. Los títulos y metadatos publicados correspondían a una versión del artículo que ya no existía. El H1 prometía una cosa, el cuerpo contaba otra.
¿Y sabéis qué es lo peor? Que este patrón no es solo nuestro. Es el estándar. Casi todos los pipelines de contenido con IA que he visto funcionan así: escribir primero, «optimizar» después, reescribir tres veces más por si acaso. Nadie se para a pensar en el orden de los agentes.
Y resulta que el orden importa bastante más que el número.
¿Cómo se organiza un pipeline de contenido que funcione?
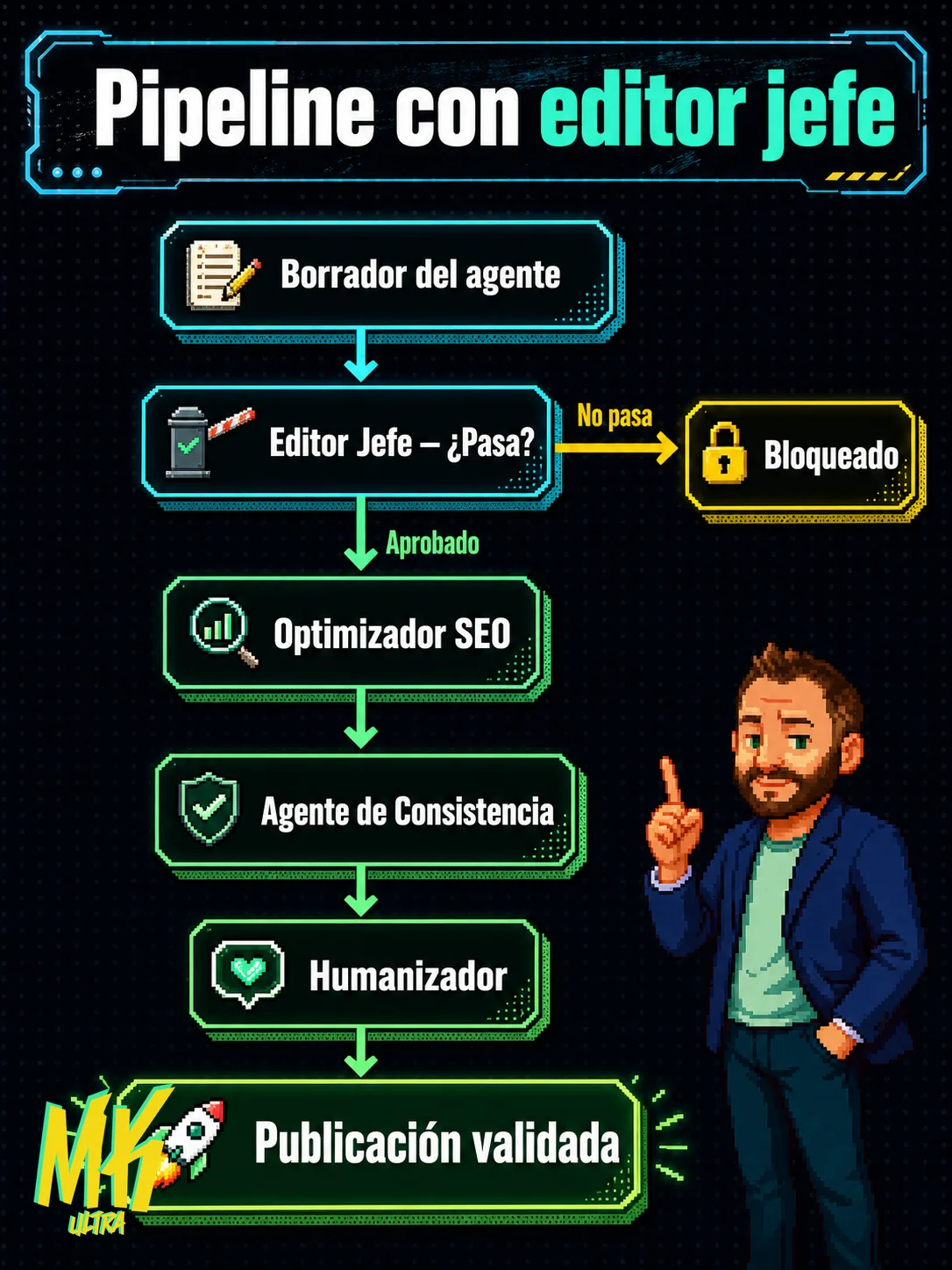
El rendimiento de un pipeline de contenido cambia por completo cuando el agente con criterio editorial revisa antes que el optimizador SEO. Igual que en un periódico, donde el editor jefe aprueba antes de que entre corrección o maquetación.
Anthropic describe esto como el patrón «evaluator-optimizer» en su guía sobre construcción de agentes efectivos: un agente evalúa la calidad, otro ejecuta. La clave no es apilar capas de procesamiento, sino colocar la evaluación en el punto correcto del flujo.
Aplicamos esa lógica y reorganizamos el pipeline como si fuera una redacción de verdad:
- Editor jefe: revisa ANTES que el SEO. Su criterio es periodístico puro. ¿Es preciso? ¿El titular refleja lo que dice el texto? ¿Hay datos sin fuente verificable? Si no pasa el corte, el artículo no avanza.
- Optimizador SEO: entra después, sobre un texto que ya es correcto. Trabaja con keywords sobre contenido validado, sin riesgo de distorsionar la verdad por meter una long-tail.
- Agente de consistencia: genera título y meta description sobre el texto FINAL. No sobre un borrador que luego muta tres veces.
- Humanizador: cierra el flujo con la voz real del autor como referencia. Replica la voz que ya existe en el corpus, tal cual.
Cada agente hace una cosa y la hace en el momento correcto. Sin reescrituras circulares ni metadatos huérfanos. Y sin títulos que prometen algo que el texto no cuenta.
La prueba de fuego: el titular inventado que no pasó
Para comprobar que el sistema funcionaba de verdad, hicimos la prueba más bestia que se nos ocurrió: colarle un titular con un dato inventado. Una cifra rotunda, llamativa, de esas que cualquier agente redactor genera sin pestañear porque «suena bien» y «mete gancho».
¿Resultado?
El editor jefe detectó que el dato no aparecía en ninguna fuente del brief. Reescribió el titular a uno fiel al contenido real pero con gancho editorial. Y documentó cada corrección con su justificación: dato no verificable, titular que no cuadraba con el cuerpo del artículo.
No tiene misterio. Es un agente con un prompt bien diseñado cuya única función es buscar incoherencias entre titular, datos y cuerpo del texto. Si algo no cuadra, lo frena. Punto.
Y eso es justo lo que necesita cualquier pipeline que aspire a publicar contenido que no dé vergüenza. Las directrices de Google sobre contenido útil penalizan contenido pobre, automatizado sin criterio, sin experiencia real. Que lo haya escrito una IA es lo de menos. Un gate editorial con criterio es supervisión real. Y eso, Google sí lo distingue.
La IA también fabrica enlaces (y nadie los valida)

La IA no solo inventa datos. También fabrica URLs. Durante la auditoría encontramos un enlace completamente ficticio dentro de un artículo. Formato impecable, dominio que existe de verdad y slug coherente con el tema. Pero la página no existía.
Si trabajas con agentes de IA para generar contenido, esto no debería sorprenderte. Es uno de los problemas más documentados de los modelos de lenguaje. Lo que sorprende es que llegue a producción sin que nadie lo compruebe.
La solución fue ridículamente simple: un paso de validación automática que lanza una petición HTTP a cada URL que un agente incluye en el texto. Si no responde con un 200, se marca para revisión manual. Lleva segundos. Y te ahorra publicar artículos con enlaces a páginas que solo existen en la imaginación del modelo.
Parece tan obvio que da pereza contarlo. Pero no estaba. Y apostaría a que en la mayoría de pipelines de contenido con IA tampoco está.
El agente que más vale no escribe: veta
Todo el mundo habla de escalar contenido con IA. Más artículos, más rápido. Y es verdad que se puede.
Pero el cuello de botella nunca fue la producción. Es la calidad.
Puedes tener 10 agentes redactando y 5 optimizando keywords. Si ninguno tiene el criterio de decir «esto no se publica», vas a escalar ruido. Y escalar ruido rápido sigue siendo ruido. Solo que más caro de limpiar.
Nosotros tardamos en verlo. Y el arreglo fue ridículo: darle a un solo agente el poder de decir que no. A veces lo más complicado de automatizar es el criterio de parar.
Preguntas frecuentes sobre pipelines de contenido con IA
¿Qué es el patrón evaluator-optimizer en agentes de IA?
Es una arquitectura donde un agente evalúa la calidad del output y otro ejecuta la tarea, documentada por Anthropic como uno de los patrones clave para construir sistemas de agentes efectivos. En un pipeline de contenido, significa poner un agente revisor con criterio editorial antes del agente que optimiza para SEO.
¿Por qué la IA inventa URLs que parecen reales?
Los modelos de lenguaje generan texto estadísticamente probable, no verificado. Pueden fabricar URLs con formato correcto, dominio existente y slug coherente porque esos patrones existen en sus datos de entrenamiento. La forma de evitarlo en producción es validar cada enlace con una petición HTTP automática antes de publicar.

