«Cambiar de modelo de IA es cambiar una variable de entorno.» Lo habrás leído cien veces. Es mentira. Mi pipeline dependía del formato exacto en que la herramienta envolvía la respuesta. Del modelo, ni caso. Y ahí es donde casi todas las migraciones de modelo de IA se estrellan.

TL;DR: El resumen sin rodeos
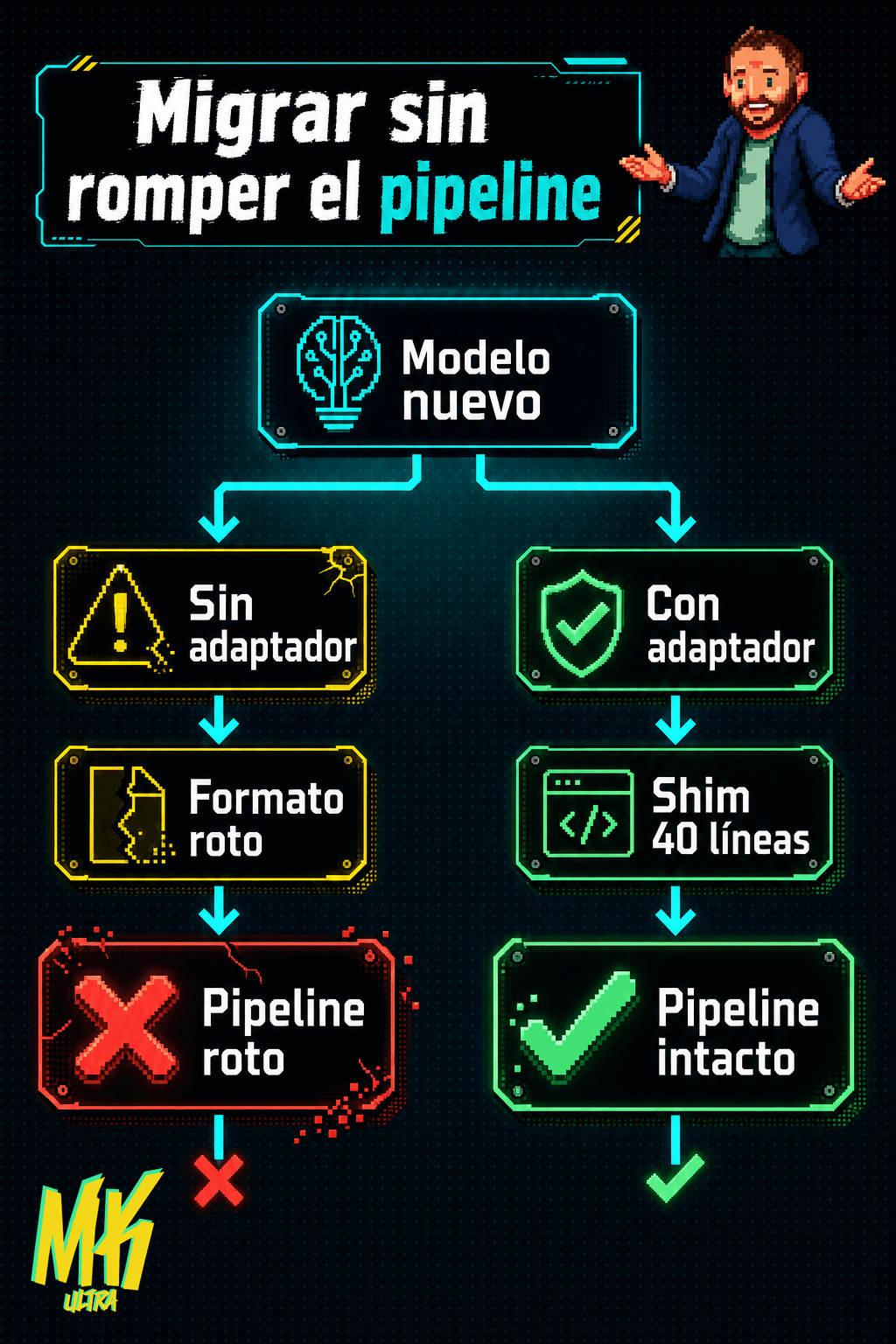
- Contrato de dos capas: Tu pipeline lee el sobre que la herramienta pone alrededor, no el modelo en sí. Cambia de modelo y el sobre se rompe.
- Shim de 40 líneas: Un adaptador que reconstruye el sobre exacto para el motor nuevo. El pipeline ni se entera del cambio.
- 0,0015 euros por ejecución: 25 veces más barato que el setup anterior, verificado en producción.
- Crítico adversarial: Otro modelo cazó 22 fallos antes de tocar producción, incluido un leak de datos privados.
Te cuento cómo llegamos aquí. Anthropic decidió cambiar las reglas del juego con la facturación de sus agentes headless. Así, como quien te sube el alquiler y te deja el papelito en el buzón. El resultado: todo mi ecosistema de automatización se fue al garete. Y cuando digo todo, digo TODO.
La verdad es que estaba asustado. Tenía un pipeline de contenido que funcionaba, que estaba probado, y que de repente dependía de un proveedor que acababa de demostrarme que las reglas pueden cambiar de un día para otro. El plan: pasar a OpenCode con una mezcla de modelos, DeepSeek para el trabajo pesado y OpenAI para tareas específicas. Parecía factible.
Hasta que miré lo que había debajo del capó.
¿Por qué migrar de modelo de IA no es un cambio drop-in?
La idea sonaba sencilla: cambiar de modelo y listo. Uno es 25 veces más barato. ¿Qué puede salir mal?
Todo.
Lo llamo el contrato de dos capas. Capa 1: lo que el modelo te responde, el texto puro. Capa 2: lo que la herramienta hace con esa respuesta antes de pasársela a tu código. Un sobre con metadatos ({result, session_id, coste, modelo...}). ¿Y sabéis qué leían mis 20 scripts aguas abajo?
El sobre. SIEMPRE el sobre.
El pipeline entero estaba acoplado al formato del sobre. La inteligencia que había dentro le daba exactamente igual. DeepSeek habla un dialecto distinto: donde esperabas un JSON limpio envuelto en papel de regalo, te suelta un stream de eventos. Un cambio «drop-in» rompía absolutamente todo: filtrado, formateo, almacenamiento.
Reescribir 20 scripts no era una opción. Ni de broma.
El shim de 40 líneas que migra tu pipeline de IA sin tocarlo
Así que hice lo único que tenía sentido: un adaptador de 40 líneas. Llama al motor nuevo, recoge la respuesta y reconstruye el formato de salida exacto que el pipeline ya espera. El handler de siempre consume la salida sin enterarse de que le han cambiado el cerebro.
Mismos campos. Misma estructura.
Incluso el detalle sucio de limpiar las comillas de bloque ```json``` que los modelos cuelan de contrabando en las respuestas. Ese tipo de guarrería que no sale en ningún tutorial pero que te revienta el parser a las 3 de la mañana (y no, no estoy exagerando).
A tu pipeline le da igual qué modelo hay detrás. Solo quiere los datos en la forma que espera. Si respetas esa forma, cambias el cerebro sin que el cuerpo se entere.
Verificado de punta a punta en la máquina de producción. Filtrado idéntico, formato idéntico.
Coste por ejecución: 0,0015 euros. 25 veces más barato que el setup anterior. Si te interesa reducir el gasto en herramientas de IA sin sacrificar calidad, el análisis de Ponytail para Claude Code va por ahí.
Céntimos. Literalmente céntimos.
¿Cuántos fallos caza un crítico adversarial antes de producción?

Antes de ejecutar nada en producción, hice algo que recomiendo a cualquiera que mueva piezas en un pipeline con IA: someter el plan entero a un crítico adversarial. Otro modelo, en modo solo lectura, cuyo único trabajo es buscar agujeros en tu plan. Intentar destrozarlo antes de que lo destroce la realidad.
Encontró 22 fallos.
Pero el gordo, el que me habría quitado el sueño durante semanas, fue este: un trabajo marcado como «público» podía arrastrar datos privados de la memoria compartida al proveedor nuevo. Datos privados viajando a un tercero sin ningún tipo de control.
¿Sabéis lo que habría pasado si eso llega a producción?
Prefiero no pensarlo.
Si vas a mover la fontanería de tu IA, pon a otro modelo a intentar destrozar tu plan antes de ejecutarlo. Es barato y te ahorra disgustos que no tienen precio. Un QA que no duerme y no tiene piedad con tu ego.
El Plan B que debes tener listo antes de migrar de proveedor de IA
Anthropic me hizo esta jugada. Mañana puede ser OpenAI. O Google. O quien sea. Las empresas de IA van a seguir moviendo fichas que afectan directamente a tu operativa, y no van a pedirte permiso. Eso es así y punto.
Lo que hago ahora en Marketing Ultra: cada vez que termino un pipeline o un flujo de automatización, la siguiente fase (SIEMPRE) es dejar preparado el Plan B. Con el adaptador listo y el proveedor alternativo probado. No «lo tengo pensado». Preparado. Cuando llegue el momento, cambias el adaptador y a correr. Si quieres entender cómo se estructura un pipeline de contenido completo sin intervención manual, el artículo sobre automatizar contenido con IA sin revisar cada paso te pone en contexto.
Te hablo desde la experiencia: la primera vez que te toca migrar con urgencia, sin un plan, sudas frío. La segunda vez, si has hecho los deberes, es un trámite de media hora.
La clave técnica es desacoplar de verdad, no de boquilla. Identifica la frontera exacta donde tu sistema consume la IA: qué campos lee, qué forma espera, qué asume. Construye un adaptador que preserve ese contrato. Así cambias de proveedor cuando quieras sin tocar tu lógica de negocio. Si quieres ver la diferencia real entre potencia y fiabilidad antes de cerrar proveedor, el análisis de Claude Fable 5 en producción merece un vistazo.
Lo único que migras de verdad es el contrato.
Y el que tenga esto claro, la próxima vez que tenga que migrar de proveedor de IA no estará reescribiendo 20 scripts a las 3 de la mañana. Estará cambiando una variable de entorno.
Esa sí.
Preguntas frecuentes sobre migración de modelos de IA
¿Cuánto cuesta realmente cambiar de proveedor de IA en producción?
El coste técnico puede ser casi cero con un shim bien construido. El coste operativo puede caer 25 veces: en este caso pasamos a 0,0015 euros por ejecución con DeepSeek a través de OpenCode. Lo que sale caro de verdad es no haberlo preparado a tiempo.
¿Qué es un crítico adversarial y para qué sirve en un pipeline de IA?
Un crítico adversarial es un modelo de IA configurado para revisar tu plan con el objetivo de encontrar fallos. Su trabajo es buscar agujeros, punto. En la migración documentada en este artículo, el crítico encontró 22 errores antes de tocar producción, incluido un leak de datos privados entre espacios de memoria.
¿Cómo evito el vendor lock-in en mis pipelines de IA?
Identifica la frontera exacta donde tu sistema consume la IA y encapsúlala en un adaptador. Si ese adaptador es la única pieza que conoce al proveedor real, el resto del pipeline es agnóstico. Cuando el proveedor cambie las reglas, solo reescribes el adaptador, no los 20 scripts de negocio que hay detrás.

