Dos semanas. Catorce días diagnosticando, preguntando, probando, descartando hipótesis. Y al final, la solución estaba en dos líneas de configuración que no estaban bien puestas.
Esto no es un post de los que te cuentan lo genial que es la IA. Es el post que me habría ahorrado un cabreo importante si lo hubiera leído antes de empezar.
El problema: agentes que «trabajan» sin hacer nada
Si has montado agentes Codex dentro de OpenClaw, o cualquier framework similar, probablemente conoces la sensación.
Le mandas una tarea al agente. El agente responde. Todo parece normal. Pero algo está raro.
En lugar de ejecutar la tarea, hacer la búsqueda, crear el archivo, llamar a la API, lo que sea, el agente empieza a responder con frases como:
- «Lo reviso y te comento.»
- «Lo tengo en cola.»
- «Estoy procesando la solicitud.»
- «Dame un momento para analizarlo.»
Y no hace nada. Literalmente nada. Solo habla.
Parece trabajar. Genera texto. Da sensación de actividad. Pero no ejecuta. No usa las herramientas que tiene disponibles. No llama a las funciones. No mueve ficha.
Es como contratar a alguien que en cada reunión toma notas y asiente con la cabeza… pero al salir no hace absolutamente nada de lo que se acordó.
El diagnóstico fallido: semanas mirando donde no era
Mi primer instinto fue el más natural: el prompt.
«Seguramente le estoy dando instrucciones ambiguas. Voy a reescribir el SOUL.md. Voy a ser más explícito en el AGENTS.md. Voy a reformular los objetivos.»
Nada.
Segundo instinto: el modelo. «Igual es que el modelo por defecto no tiene capacidad suficiente para razonar con las herramientas.» Probé cambios de modelo. Tampoco.
Tercer intento: diagnóstico asistido. Le pedí a Claude, incluyendo acceso con navegador para revisar la configuración directamente, que me ayudara a identificar el problema. Revisamos logs, configuraciones, instrucciones. Nada concreto. Hipótesis, posibles causas, sugerencias genéricas. El diagnóstico apuntaba a que «podría ser el contexto» o «quizás las instrucciones no son suficientemente directivas».
Seguí mirando el sitio equivocado.
El problema no estaba en el qué le decía al agente. Estaba en el cómo estaba configurado para razonar y para acceder a sus propias herramientas.
La solución inesperada: un hilo de Reddit
Dos semanas de diagnóstico sin resultado. Y la respuesta llegó de donde menos lo esperaba: un hilo de Reddit.
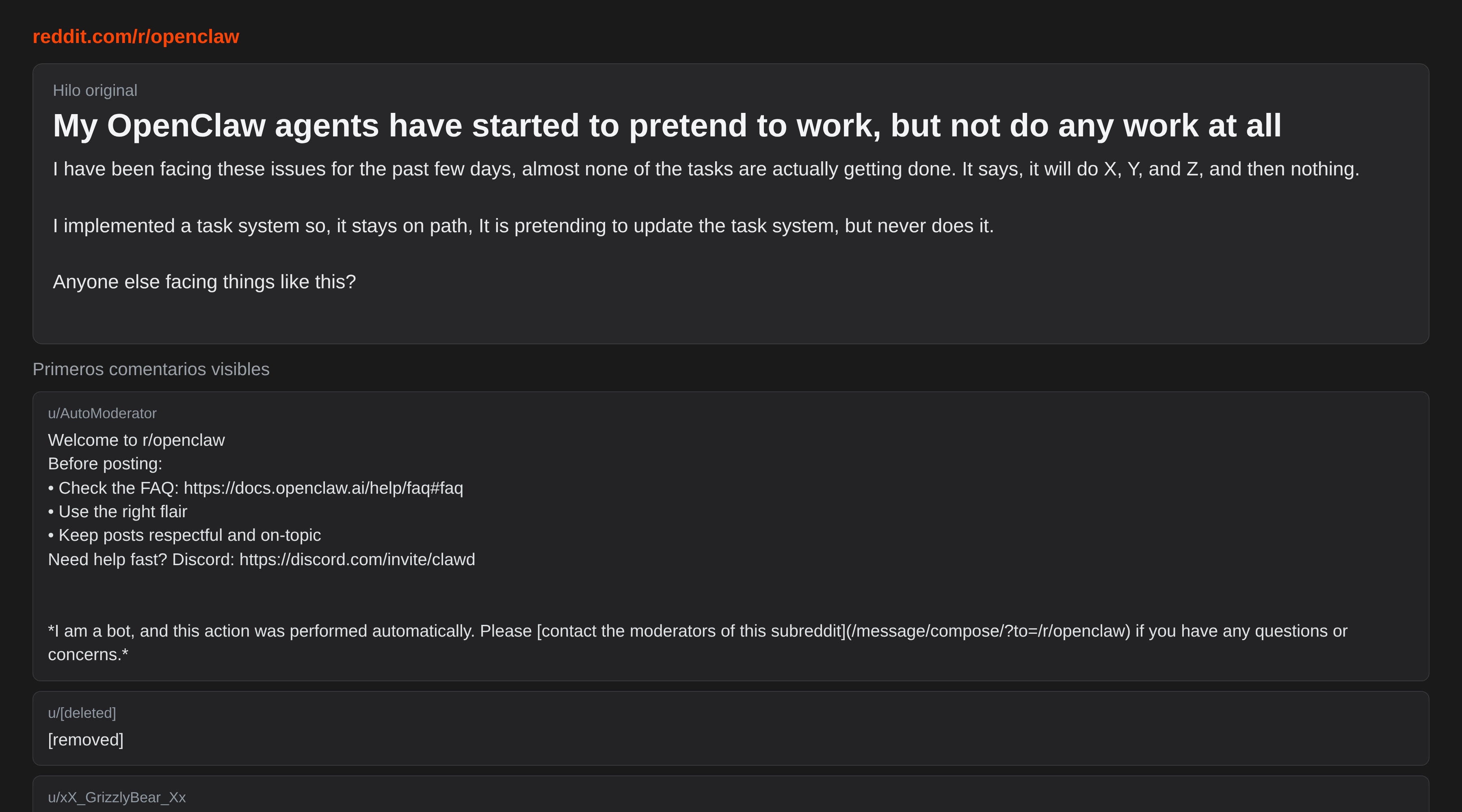
Captura del hilo de Reddit que detonó el fix (thinking + tools.profile).
Un usuario de r/openclaw, u/rayz_7777, había abierto un hilo que ya desde el título lo decía todo: «My OpenClaw agents have started to pretend to work, but not do any work at all». Mis agentes han empezado a fingir que trabajan, pero no hacen nada en absoluto.
El cuerpo del post podría haberlo escrito yo:
«It says, it will do X, Y, and Z, and then nothing. I implemented a task system so, it stays on path. It is pretending to update the task system, but never does it. Anyone else facing things like this?»
Sí. Exactamente eso. Palabra por palabra.
El hilo tenía 25 upvotes, un 96% de ratio positivo y 67 comentarios. No era un caso aislado. Era un problema que mucha gente estaba teniendo y que nadie había documentado bien en ningún sitio oficial. El propio OP, con humor, resumió el problema en una frase: «These agents are learning all the bad habits from humans.»
Y en los comentarios, alguien apuntaba la solución: no era el prompt. Era la configuración de runtime.
👉 My OpenClaw agents have started to pretend to work, but not do any work at all, r/openclaw
Fue uno de esos momentos en los que lees algo y piensas: «¿cómo no se me ocurrió antes?»
Porque la respuesta era sorprendentemente concreta. Y fácil de aplicar.
El fix técnico: thinking + tools.profile
El fix era doble. Dos parámetros en la configuración del agente Codex que no estaban activados correctamente:
- thinking: «medium»
- tools.profile: «full»
¿Qué hace cada uno? En cristiano:
thinking: «medium»
El parámetro thinking controla el nivel de razonamiento interno del agente antes de responder. Cuando está desactivado o en un nivel bajo, el agente tiende a responder de forma reactiva, superficial. Genera texto que parece una respuesta, pero no ha pasado por el proceso de razonamiento necesario para decidir qué herramienta usar, cuándo usarla y cómo encadenar las acciones.
Con thinking: "medium", el agente activa un nivel de razonamiento interno que le permite planificar antes de actuar. En la práctica: deja de ser un loro que repite frases bonitas y empieza a ser un agente que ejecuta.
tools.profile: «full»
El parámetro tools.profile define qué herramientas están disponibles para el agente en tiempo de ejecución. Cuando no está configurado explícitamente como "full", el agente puede estar operando con un conjunto reducido de herramientas, o incluso sin acceso real a ellas, sin saberlo.
Esto explica perfectamente el comportamiento que veía: el agente «sabía» que tenía que ejecutar algo, pero no tenía acceso real a las herramientas para hacerlo. Entonces hacía lo único que podía hacer: responder con texto. Cubrir el expediente verbalmente.
Con tools.profile: "full", el agente tiene acceso al perfil completo de herramientas configuradas. Y puede usarlas.
Resultado después de aplicar los dos cambios: comportamiento normalizado al instante. Los agentes empezaron a ejecutar. Sin tocar ni una línea de los prompts.
El patrón generalizable: revisa el runtime antes de tocar el prompt
Aquí está la lección que me llevo y que creo que es útil para cualquiera que esté montando pipelines con agentes.
Cuando un agente no hace lo que esperas, el instinto natural es mirar el prompt. «Estoy explicándome mal. Tengo que ser más específico. Le falta contexto.»
Y muchas veces eso es correcto. Pero no siempre.
Hay una capa que va antes del prompt: la configuración de runtime. Y si esa capa está mal, da igual lo bien que escribas las instrucciones. El agente no puede ejecutar porque el entorno no se lo permite.
Antes de reescribir el SOUL.md por décima vez, comprueba esto:
Checklist de runtime para agentes Codex
- ✅ thinking: ¿Está configurado? Para tareas que requieren toma de decisiones o encadenamiento de acciones:
"medium"o"high". - ✅ tools.profile: ¿Está en
"full"? Si no está explícitamente configurado, el agente puede operar con herramientas limitadas o ninguna. - ✅ Modelo: ¿El modelo asignado soporta uso de herramientas? No todos los modelos tienen capacidades de function calling activas por defecto.
- ✅ Permisos de herramientas: ¿Las herramientas que necesita el agente están declaradas en su configuración? Un agente no puede usar lo que no sabe que tiene.
- ✅ Logs de ejecución: Antes de diagnosticar el prompt, mira los logs. ¿El agente intenta llamar herramientas y falla, o directamente no las llama? Son problemas distintos con soluciones distintas.
Si todo esto está bien y el agente sigue sin ejecutar, entonces sí: toca revisar el prompt. Pero empieza por aquí.
Por qué esto importa más allá del caso concreto
Llevamos un tiempo en el sector con mucho hype sobre agentes de IA. Muchos artículos sobre lo que pueden hacer, sobre el futuro del trabajo, sobre automatización.
Pocos hablan de lo que pasa cuando no funcionan. Y de que cuando no funcionan, el error casi nunca está donde parece.
Los agentes no son magia. Son sistemas con capas: modelo, runtime, herramientas, instrucciones, contexto. Cuando algo falla, puede fallar en cualquiera de esas capas. Y el ruido que genera el fallo, el agente respondiendo con texto vacío, pareciendo activo sin estarlo, puede enmascarar completamente dónde está el problema real.
Mi error durante dos semanas fue asumir que el problema era de capa alta (el prompt) cuando era de capa baja (el runtime). Una vez entendí eso, la solución fue trivial.
Así que si estás montando pipelines con agentes y te encuentras con este comportamiento, agentes que responden pero no ejecutan, que parecen trabajar pero no mueven ficha, que generan texto donde debería haber acciones reales, empieza por el runtime. Comprueba thinking y tools.profile. Probablemente estés más cerca de la solución de lo que crees.
Dos semanas de diagnóstico. Dos líneas de config. Así está el asunto.
¿Te ha pasado algo parecido?
Si estás trabajando con agentes Codex, OpenClaw, o cualquier framework de agentes y te has encontrado con comportamientos similares, me interesa saber cómo lo resolviste.
Cuanto más compartamos este tipo de casuística concreta, no los tutoriales de «cómo montar tu primer agente en 10 minutos», sino los problemas reales con los que te atascas, más rápido avanzamos todos.
Deja tu experiencia en los comentarios. O si conoces a alguien que esté peleando con agentes que no ejecutan, comparte esto. Igual le ahorras dos semanas.
PD. Lo más gracioso de todo es que después de dos semanas buscando el problema en los prompts, la solución estaba en los parámetros de runtime del framework. A veces uno se complica solo.

